简介
Google File System是谷歌开发的分布式文件系统,GFS虽然也像之前的分布式文件系统一样希望能够达到较好的性能、扩展性、可靠性、可用性,但是其设计主要是从各种使用GFS的应用的工作负载以及环境来出发的。设计GFS时,开发者对GFS的实际使用环境做出了一系列的假设,包括:
- 系统构建在很多较为偏移的商业机器上,这些机器很有可能出现错误
- GFS存储的文件一般都较大
- 应用的工作负载主要为大量的顺序读取和少量的随机读
- 应用的工作负载有大量的顺序写,文件在写入后很少会进行修改
- 系统需要有效的处理多个客户端并行向同一个文件尾追加内容的操作,这是由于GFS中很多文件被用作构建生产者消费者队列或多路归并
- 保证高的可持续的带宽利用率比保证请求的低延迟更重要
GFS架构
一个GFS集群由一个Master和多个Chunk Server构成,同时可能有多个客户端来访问这个集群。
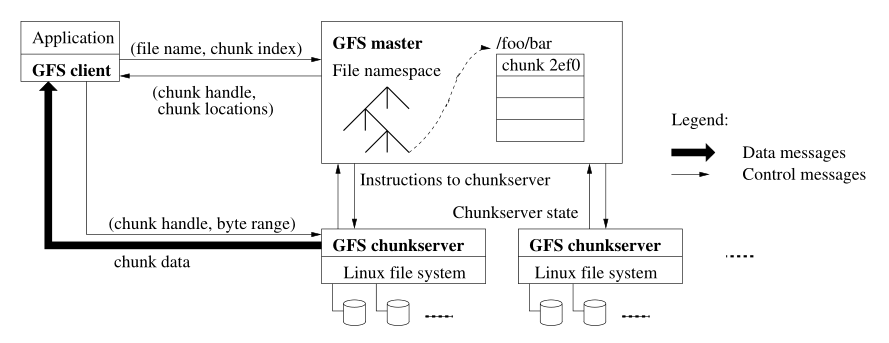
Master
在整个GFS集群中仅会有一个Master,该Master会负责系统元数据的管理,并负责处理一些系统范围内的事件,例如块的租约的管理、文件系统命名空间的管理、垃圾回收等。让系统中仅包含一个Master是为了简化整体系统的设计,让这个Master能够基于全局的信息来进行块的配置以及调度,但由于仅有单个Master可能会导致该机器成为整个系统的瓶颈,也有可能出现由于Master崩溃而导致整个系统不能正常工作的情况的出现,因此GFS在设计时会尽量减少Master的负载,并将Master的重要数据写入磁盘及远程机器中来避免Master的失效影响整个集群的运行。接下来介绍以下GFS的Master主要的功能:
管理系统元数据
GFS管理的元数据主要有三类:1)文件及块的命名空间,2)由文件到块的映射,3)块的位置。其中前两种信息除了会保存在内存中还会写入磁盘及远程机器中来防止Master的崩溃,而块的位置则仅在Master启动时从各个Chunk Server中拉取,这样做的原因是为了简化Master的设计,同时由于仅有Chunk Server才有其保存了哪些块的话语权,因此也没必要在Master中保存所有的信息。GFS中为了前两种元信息使用了操作日志(Operation log)来记录所有的对元信息的更改,如果Master崩溃则只需重放日志就可以恢复到原有状态,为了减少重放的时间GFS还对日志设置了检查点。
系统事件的处理
命名空间的管理及锁的管理
由于很多操作如对某个文件夹的快照可能需要较长时间才能完成,因此GFS通过允许同时多个操作的并发及对不同范围的数据加锁来确保一定的顺序。例如某个客户端正要求对/home/user进行快照然后保存至/save/user中,此时GFS需要进行一定的控制来保证此时不会有其他客户端在/home/user文件夹中创建新的文件。该例中,Master会获得/home及/save的读锁以及/home/user的写锁以及/save/user的写锁,如果希望在/home/user中创建文件则需要获得/home及/home/user的读锁以及/home/user/filename的写锁,此时由于无法获取已有的锁,因此无法创建文件。这种锁机制来源于GFS对文件夹的管理特定,因为与传统文件系统不同的是GFS并不会为某个文件夹创建一个特殊的数据结构,这样允许了同一个文件夹内能够进行多个并发的操作,例如创建多个文件。
块的管理
Master需要对所有的块进行管理,当新的块创建时需要选择为这个块选择新的位置,当某些Chunk Server负载过高时需要进行块的迁移,某些Chunk Server失效时会进行块的复制来保证可用性。在进行块的创建时需要考虑下列因素:
- 将新的块放置在磁盘利用率较低的Chunk Server中
- 避免在同一个Chunk Server短期内创建大量的块,因为刚创建的块可能不久后就需要进行写入,从而为该服务器带来较高的负载
- 保证块在不同机架(rack)服务器上的分配
- 将数据分不到不同机架上的服务器来避免由于交换机或电力等原因导致多个服务器同时失效,从而提升数据的可靠性和可用性
- 最大化网络带宽利用率
垃圾回收
当GFS中的文件被删除后并不会直接将块回收,而是周期性的让垃圾回收机制来释放实际的物理存储空间。这样可以简化系统的设计并使之可靠性更高。
当应用删除一个文件时,Master会将这个操作记录到日志中,然后将这个文件重命名。Master会周期性的扫描命名空间,当发现某个文件已经被删除有一段时间了则正式删除这个文件,在此之前该文件尚能被用户恢复。同时Master会周期性的扫描块的命名空间,如果发现某个块并没有被任何一个文件所引用,则删除为这个块保留的元信息,之后在Chunk Server与Master交换心跳包时Chunk Server会告知Master自己存有哪些块,Master会确定其中哪些块已经被删除,然后让Chunk Server删除这些块。使用这种方法进行块的垃圾回收的主要缺点是由于块需要等待一段时间才能真正的从Chunk Server上删除,因此可能导致难以进行存储空间的控制,因此GFS允许用户显式的再次删除文件来立即触发存储空间的回收。
陈旧的块的检测
Master会为每个块维护一个版本号(chunk version number)来确定,当Master给出一个块的租约(lease)后会增加这个版本号,并通知所有存储着最新的块的Chunk Server。如果Chunk Server来与Master交换信息时发现其存储的块的版本号过小则认为其存储的是过时的信息,并会在之后的垃圾回收过程中删除这个块。
客户端操作
客户端操作流程的设计的出发点是减少各种操作过程中Master的参与,从而降低Master的负载。
客户端进行读流程
- 客户端将需要读写的位置转换为块的序号
- 客户端将文件名及块号发送给Master,来查询对应的块的句柄及存储块的所有Chunk Server的位置
- 客户端将Master的信息缓存直到过期或文件被重新打开
- 客户端将从Chunk Server中选择一个较优的服务器来请求数据
客户端进行数据变更流程
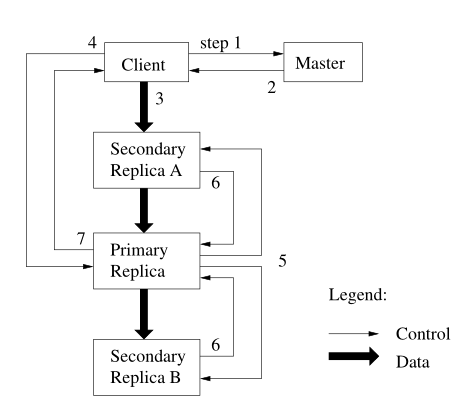
当客户端需要进行某个块的内容或者元数据的变更时,如果某个写入请求过大跨过了块的边界,则客户端会将这个写入请求拆分为多个写请求。GFS会保证其中的每个变更能够在块的所有副本上进行,为了保证这一结果,GFS使用了租约(lease)。Master会给与块的某个副本一个租约,并称该副本为Primary,该副本会负责为所有针对该块的变更选择一个顺序,因此全局所有变更的顺序取决于租约的顺序,在同一个租约期内则取决于Primary为变更分配的序列号。
客户端进行数据变更的流程如下:
- 客户端请求Master来获取Primary与其他副本的位置,如果没有副本拥有租约则Master会分配一个
- Master向客户端返回Primary及其他副本的位置,客户端将这些信息缓存起来
- 客户端将数据推送给所有的副本,Chunk Server收到数据后会将其缓存至一个LRU的缓存中
- 当所有副本都确认收到数据后,客户端将向Primary发送写入请求,Primary会为这个写入请求选择一个序号,并按照序号来应用变更
- Primary将所有的写请求发送至其他副本中
- 其他副本收到请求后应用这个写请求并反馈给Primary
- Primary发送回复给客户端,如果任何副本的写入失败都会作为回复的请求发送给客户端
GFS通过将进行数据修改时的控制流程与数据流程分离来获得较高的性能。修改时的控制流程会是由客户端到Primary,再从Primary到其他所有副本。而在客户端将数据推送到所有副本时,会将所有副本串成一条链,然后数据沿着这条链进行转发,转发时还使用了流水线来降低转发的延迟。
客户端进行原子性的追加
由于使用GFS的大多数操作是在某个文件结尾处追加数据,因此GFS提供了一个原子性的追加操作,保证追加的数据能够至少一次原子性的追加在文件结尾。进行原子性追加操作的流程与上一些描述的相同,仅在Primary处稍微有所不同。当追加内容时,如果发现此次的追加会导致越过块的边界,如果是则将块的剩余空间填满,然后告知客户端在下一个块进行重试,当让每次追加的内容的大小最大是块的1/4,因此不会出现一致填充的情况;如果没有越过边界,则Primary将数据添加至块的尾部,然后告诉所有副本在相同偏移处写入同样的数据。如果某个副本的追加操作失败了,则客户端会重试该操作,因此此时可能出现同一个块的不同副本之间内容并不是完全一致的情况。
快照
GFS进行快照的速度非常快,其在进行快照时会使用Copy-On-Write来减少懒惰的进行复制。当Master收到快照请求时会首先取消所有已有的租约,之后所有客户端与对应块的读写都需要与Master进行沟通,因此Master可以在收到请求后才进行块的复制。
一致性模型
为了讨论GFS的一致性模型必须首先定义以两个词。一致(Consistent),如果文件的某个部分在所有客户端无论访问那个副本都会获取相同的数据则称其是一致的。定义的(Defined),如果如果一个文件内容的变更是一致的,且所有客户端可以看到其所有的变更内容则称其是定义的。
如果仅有单个客户端在向该区域写数据则其是定义的,如果由多个客户端同时对某个区域进行写入,且操作都成功了,则其是一致的,但可能不是良好定义的,因为其可能混合这多个客户端的写入。如果对某个区域的写入失败了,则其是不一致的。
接下来简要介绍上图。序列化的写入一致是良好定义的,因为客户端会在一个位置进行写入操作并成功,保证所有的副本在该位置的内容都是一致的,且由于没有其他客户端并发的写入,所以一定能反映该客户端的所有修改。序列化的追加最后一个位置是有良好定义的,但其中某些部分可能是不一致的,该原因可能是客户端尝试追加操作失败,导致不同副本的不一致,但之后重试时会在相同的偏移处追加相同的数据,然后成功,但前面可能有部分数据不一致的情况。并发成功的写入是一致但不是良好定义的,因为写入操作可能由于过大被拆分为针对多个块的写入,因此每个块都是一致的,但是没有反映任何一个客户端的写入内容。并发追加也是部分是良好定义的,但其之后可能有些部分是不一致的,情况同序列化追加一致。
容错
为了保证在各种机器出错情况下GFS的可用性,GFS将块进行复制,并将其分布到不同的机架上,并将Master的状态进行复制,当已有Master失效时会启动新的Master,然后根据日志来构建状态。同时GFS还提供一些shadow master来提供一些稍旧的信息。为了保证存储的信息没有损坏,GFS会为数据计算校验来检验数据是否已损毁。